Mathematics
What does it mean to major in mathematics?
Mathematics majors study numbers, solve problems, think critically, and become proficient in the underlying language that flows through all of the sciences. Students can choose between the Bachelor of Arts and Bachelor of Science in Mathematics. The BA degree allows greater compatibility with other areas of study while the more specialized BS degree provides in-depth training pure, discrete, or applied mathematics, statistics, mathematics and computer science, or finance and actuarial science. The BS degree has an optional emphasis in statistics.
Students who major in mathematics are analytical thinkers who can solve problems in creative ways. They gain a broad knowledge of both theoretical and applied mathematics, and gain facility in the use of technology that can transfer their knowledge easily to other areas of inquiry.
The fact sheet provides a summary of the major, information about the program, and our alumni. The degree sheet for the BA degree and the degree sheet for the BS degree give the specific requirements and a sample 4-year curriculum plan.
Minor in mathematics?
A minor in mathematics is a great combination with any of the science, engineering, business, or accountancy majors. It consists of (1) Math 261 or 271; 262, 263, 264, and one 3-hour course at the 300 level or above; or (2) Math 261 or 271; 262, 263, and two courses at the 300 level or above.
Why is UM a good place to study mathematics?
The mathematics faculty have areas of expertise in matroid theory, graph theory, functional analysis, statistics, analytic number theory, complex analysis, commutative algebra, probability theory, dynamical systems, sympletic topology, and mathematical physics.
The department offers opportunities for undergraduate research, conference travel, and participation in local and national academic competitions. Mathematics undergraduate students participate in seminar talks that are tailored to their career and mathematical interests.
The department recognizes the role of technology in the classroom, and its courses have evolved accordingly. Computer projects are included throughout the calculus sequence, allowing students to develop software skills that are also used in later mathematics classes and in other classes across campus. Students in applied statistics use computers to conduct statistical analysis. Computers are integrated into our freshman-level classes, too. Mathematics is not a spectator sport; it is best learned by doing. As part of their learning experience, students spend significant time in our mathematics laboratory, where they interact with learning software that challenges and hones their skills. In the lab, learning is dynamic and feedback is immediate. Tutors are also on hand to offer one-on-one assistance.

Faculty Profile
Dr. Saša Kocić, Associate Professor of Mathematics, earned his PhD from the University of Texas, Austin. His research interests include dynamical systems, ridigity theory, KAM theory, and renormalization. Dr. Kocic was chosen in a new grant competition funded by the National Science Foundation’s Established Program to Stimulate Competitive Research (EPSCoR) to develop collaborations with other premiere research institutions around the nation. His collaboration with the University of California-Irvine will develop tools for studying dynamical systems, allowing mathematicians to obtain new results by looking at systems at different spatial and time scales, revealing shared properties.
Why study mathematics at UM? “Mathematics provides students an opportunity to develop their logical thinking and problem solving skills and broaden their possibilities in the future. These skills are crucially important not only for mathematicians, but also for a wide range of professions – from software engineering to investment banking. Our department is a vibrant, rapidly expanding environment with many young faculty eager to work with students individually and help them succeed.”
What can mathematics majors do after graduation?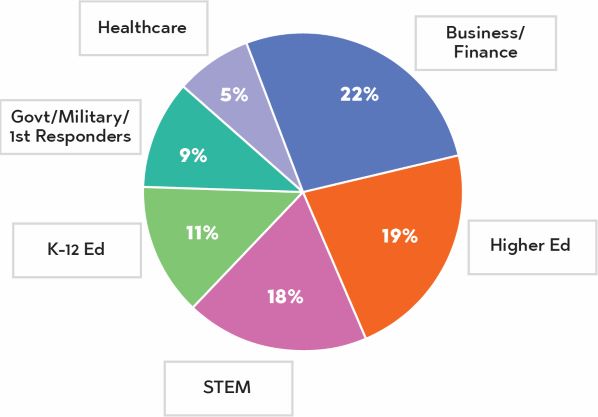
A liberal arts education empowers and prepares students to deal with complexity and change through a broad knowledge of the world. They gain key skills in communication, problem-solving, and working with a diverse group of people. Related careers in mathematics include education, research, information technology, engineering, finance, actuaries, accounting, banking, health, statistical analysts, national intelligence, and law.
Our undergraduate math alumni are found in many sectors of the economy, with the top six sectors shown in the infographic to the right. The largest percentages are working in business and financial firms, higher education, and STEM companies such as IT, energy, manufacturing, and science firms.
Alumnus Profile
Samuel Watson (BS mathematics, physics; BA classics ’08; MS mathematics ’09)

“My interest in math was kindled by my middle school teacher Ann Womble. She introduced me to math competitions, and I was drawn to the creativity and intellectual challenge of problem solving. In high school and college, my math experiences became more collaborative, and I felt confident pursuing my educational opportunities in math because I enjoyed both the individual and the community aspects of the subject.”
Samuel was an honors student and received awards in classics and mathematics. His service included writing exams for the university’s high school math contest and coaching the Oxford Middle School Mathcounts team to a state championship.
He received a Goldwater Scholarship and Gates Cambridge Scholarship to study mathematics at the University of Cambridge. He completed his PhD in mathematics at MIT on a National Science Foundation fellowship. He is now the Director of Graduate Studies in the Data Science Initiative at Brown University. He researches fractal curves and surfaces which emerge from the study of geometric arrangements of microscopic randomness, and he trains students from a variety of backgrounds for careers in data science.
Why study mathematics at UM? “Math is an excellent discipline because mathematical ideas have recently been leveraged to profound effect in the social sciences, physical sciences, business, finance, and other fields. Honing your mathematical problem solving skills in college puts you in position to be at the forefront of these developments. The UM math department in particular provides a welcoming and supportive learning environment. You will have invaluable opportunities for mentorship from professors who care about you as an individual.”
For more information
Dr. James Reid, Chair and Professor of Mathematics
Department of Mathematics
305 Hume Hall
The University of Mississippi
University, MS 38677
(662) 915-7071 | mdepart@olemiss.edu